Expanding OSINT: Using Named Entity Recognition for Data-Driven Analysis and Visualization
Hello! I am back after going through a hibernation period.
Although most of my blog is composed of OSINT challenges, I want to expand my horizons and focus on producing blogs that engage in data analysis, AI and computational linguistics for conducting OSINT.
This blog will demonstrate the applicability of Named Entity Recognition in OSINT for gathering and visualising relevant information pertaining to EU pdf reports on Sudan.
I would like to pre-face that this data-driven approach is not meant to be a replacement for close analysis, rather an aid that can point to interesting patterns or relationships within the data that can then warrant further exploration.
What is Named Entity Recognition?
Named Entity Recognition (hereafter NER), is a Natural Language Processing model that extracts pre-defined categories within a text. The categories can consist of things such as organizations, quantities, human names, locations, etc. What NER does is process the text and classifies each entity present in their corresponding categories.

NER visualization using the first 500 characters of EU press report on Sudan 16/12/2024
Applicabilities for OSINT
NER (Named Entity Recognition) is a tool pulls structured information out of large amounts of unstructured textual data, making it possible to identify and extract relevant entities. It’s useful for classifying important sources, analyzing how often specific entities appear, and spotting patterns where entities show up together in the same document, paragraph, or sentence.
Beyond just structuring data, NER can help with geolocation and mapping by identifying location-based entities like cities, countries, or landmarks to create geospatial insights. Temporal analysis is another benefit, allowing the extraction of dates to build timelines and understand the order of events. Tracking and grouping entities over time also makes it easier to monitor and detect trends. On top of that, identifying entities such as people, places, or organizations can be valuable for incident detection.
Demonstration: EU pdf reports and press releases on Sudan
One of the key principles of the EU is access information and transparency. Through this we are able to access a myriad of documents that the europa.eu domain offers to the public. The abundance of so much documentation makes it so that there is a lot of text to sift through, although the EU does offer infographics and summaries of specific issues or events, the brevity of these sources leaves much detail to be desired.
This demonstration contains 19 pdfs from the EU pertaining to Sudan, with a total of 102330 words. The pdfs range from reports, press releases and parliament journals.

Table summarising textual data word count
Getting started with the SpaCy model
For this demonstration I used the SpaCy NER model. The model is designed for efficient and easy-to-use processing of text data. spaCy’s NER provides pre-trained models that identify and categorize named entities in the text into predefined classes, such as:
PERSON: Names of people (e.g., "John Doe")
ORG: Organizations (e.g., "United Nations")
GPE: Geopolitical entities (e.g., "France", "New York")
LOC: Non-GPE locations (e.g., "Mount Everest")
DATE: Dates (e.g., "January 1, 2025")
TIME: Times (e.g., "3 PM")
MONEY: Monetary values (e.g., "$100")
PERCENT: Percentages (e.g., "50%")
After running the NER model on all of the documents, we get a list of tuples as an output as shown below:

Example of NER output
Now we can shape and organise the data to make it more readable depending on what we’d like to look at.
Mapping the locations
We can map the locations based on the Geopolitical entities (GPEs) tags as shown below on a SVG map made with plotly.js.

SVG map summarising Geopolitical entities mentioned in documents, made using plotly.js
We can also get some basic statistics and see the frequency of the most prominent GPEs mentioned in the documents with matplotlib.
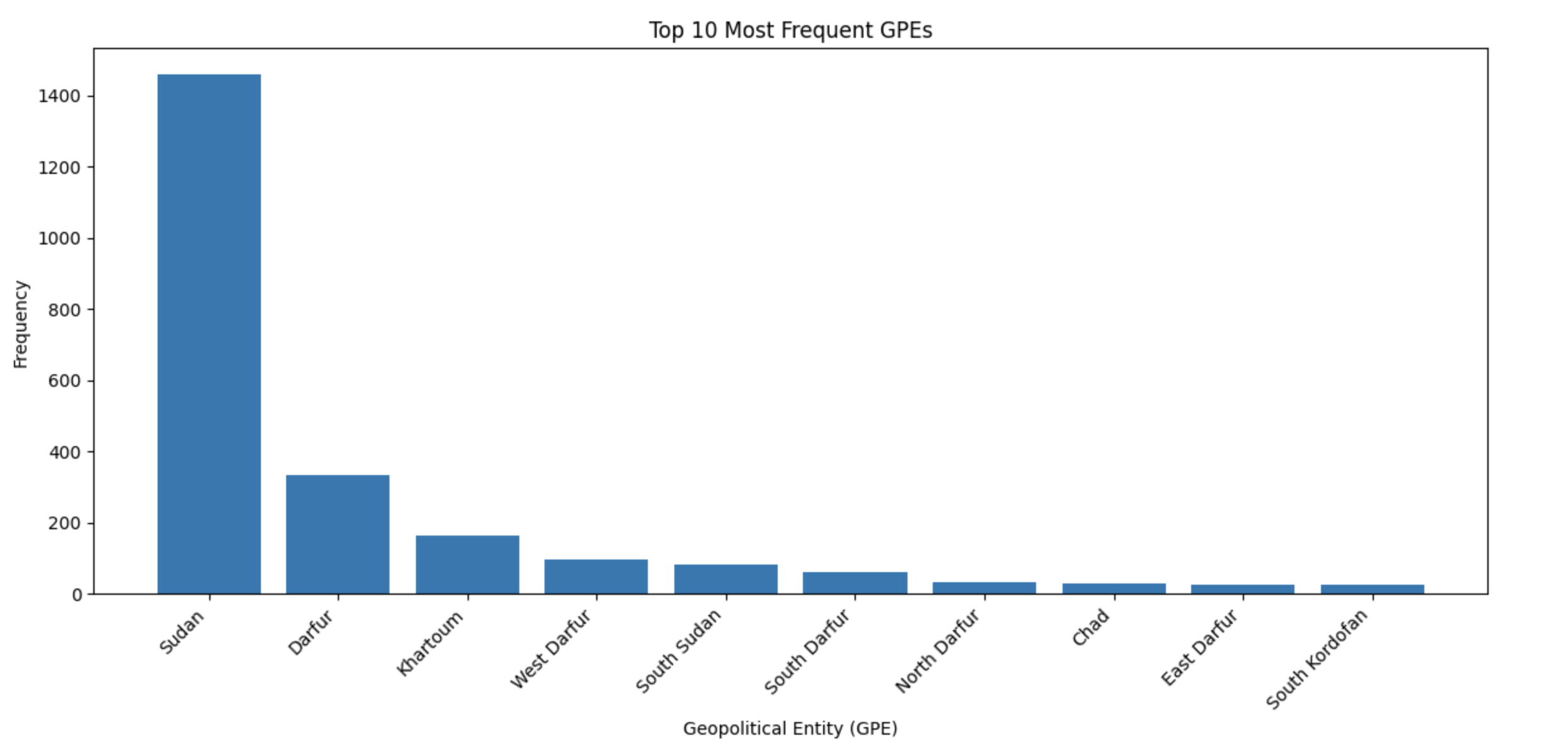
Count of top 10 GPEs mentioned in the documents
As expected from these results, Sudan and its cities such as Darfur, and its regions such as East Darfur are prominent in the data. We also see mentions of neighbouring countries such as Chad and South Sudan. When looking at the SVG map, we are also able to see the mention of other countries outside of the African continent.
This information allows us to go from the macro to the micro, when looking at the SVG map I became curious to see countries such as China mentioned in the documents. Based on this we can zoom in and find the context in which China was mentioned and exactly in which document(s) with using the .find() function in Python to sift through the data frame.
for index, row in df.iterrows():
text = row['text']
if 'China' in text:
start_index = max(0, text.find('China') - 150)
end_index = min(len(text), text.find('China') + 150)
print(f"Found in row {index}:\n{text[start_index:end_index]}")Output:
Found in row 0: ia and the UAE supported the overthrowing of Al -Bashir in 2019, and have sided with Hemedti , who provided them with troops to fight in Yemen . China and Russia have invested heavily in ext r a cting Sudanese natural resources and it is expected that they will try to preserve their econom Found in row 13: he importance of the reconciliati on and compensat ion of victims and that all displaced people have the right to return to their places of origin. China 's influence The role of China is essent ial; this has beco me a mantra for those want ing to find a solution in Sudan as well as those who are
Based on the information provided, we can now get more context regarding China’s relation to Sudan in a streamlined manner.
Extracting prominent organisations
NER also lets us extract organisations.

Here we can see a breakdown of the most frequently mentioned organizations in the documents. the RSF is predominant and refers to the Rapid Support Forces in Sudan. interestingly enough, a media source called Radio Dabanga is also prominently mentioned in the documentations.
NER has extracted concrete organizations such as the UN or the EUAA, but it has also included some more abstract groups such as ‘the Panel of Experts’.
Overall we can see an interplay between humanitarian aid organizations, media, and a predominance of military organizations across the documents.
Out of curiosity we can see the frequency of some of these organizations across each document.

Most of the organizations are predominantly present in document 18, which makes sense as this is the longest document in the dataset. Based on this information, we can also exclude document 18, and see the frequency of the predominant organizations.

After excluding document 18, we can see that the distribution of the most frequently mentioned organizations has changed.

Based on the information above, more insight can be gathered regarding the organizations that co-occur within each text. Such as WFP and GIZ being frequently mentioned together, which are two organizations with overlapping goals and projects of supporting the Sudanese population pertaining to food distribution and farming initiatives.
Fetching human names
We can also use NER to get relevant names of individuals.

Although NER did a pretty good job at extracting names, it did confuse some city names with human names such as Nyala which refer to a city or Mahamid which refers to a clan.
Although these issues with misidentifying human names can occur, the advantage is that we can always zoom into the text and see in which contexts these entities appear in as the example below shows:
Name 'Nyala' found at index 8 in the following snippet: fur and South Darfur (El Fasher, El Geneina and Nyala ). 16. Provision of air services to allow acce -------------------------------------------------- Name 'Nyala' found at index 15 in the following snippet: idential areas, notably in Khar toum, Omdur man, Nyala (South Darfur) and in Nor th Kordofan, documente -------------------------------------------------- Name 'Nyala' found at index 16 in the following snippet: idential areas, notably in Khar toum, Omdur man, Nyala (South Darfur) and in Nor th Kordofan, documente -------------------------------------------------- Name 'Nyala' found at index 18 in the following snippet: , after gaining control of strategic cities like Nyala, Zalingei, El Geneina and Ed Daien in greater -------------------------------------------------- Name 'Mahamid' found at index 4 in the following snippet: r , as well as a prominent tribal leader of the Mahamid clan affiliated with the RSF in West Darfur. On t -------------------------------------------------- Name 'Mahamid' found at index 15 in the following snippet: SSEL Masar ASILGender: male Function: Amir of the Mahamid clan in West Darfur; Member of the Native Admini -------------------------------------------------- Name 'Mahamid' found at index 16 in the following snippet: SSEL Masar ASILGender: male Function: Amir of the Mahamid clan in West Darfur; Member of the Native Admini -------------------------------------------------- Name 'Mahamid' found at index 18 in the following snippet: to various branches , with the largest being the Mahamid, Mahariya, and Nawaiba ,619 which are common to --------------------------------------------------
Based on the extracted names we can also devise a network graph to get a spatial visualization of the relations between each name.

Network map of names made with Gephi
This network map consists of Sudanese figures, members of the EU, diplomats, scholars and journalists.
The thickness of each edge (the lines connecting the nodes) represents the weight or strength of the connection. In this case, it reflects how often names appear together in the texts.
For example, the thick edge between Hemedti (head of RSF) and Bashir (former Sudanese president) shows a strong co-occurrence. Edge thickness also helps visualize when individuals are referenced in different ways, like Tubiana and Jérôme Tubiana, who are actually the same person.
Limitations
Like every tool, NER has some limitations. For instance, NER models can struggle with ambiguous sentences. This can be overridden by providing custom knowledge bases for the model to improve its accuracy. In my example I used the regular English model that comes with SpaCy’s NER, but custom models can be built according to the use case. This is especially poignant when there are either cultural differences in the content or it includes new information in which the standard model has not been trained on.
As shown in the demonstration, NER can also struggle with different names and aliases. For instance, when individuals were referenced by only their last name or first name as opposed to their full name, NER considered them to be different entities. Depending on your use case this can either be an advantage or a hindrance.
Conclusion
Despite such limitations, NER combined with other visualization techniques can offer a starting point for extracting valuable information. The main advantage of NER is that it has the ability to produce a structured output of large amounts of usntructured textual data, which can have its applications for OSINT and other textual analysis scenarios.
Through Natural Language Processing tools such as these, there is the potential to leverage the age of Big Data and its tools to provide actionable insights, leads and overviews.
See you all next time, stay curious! <3